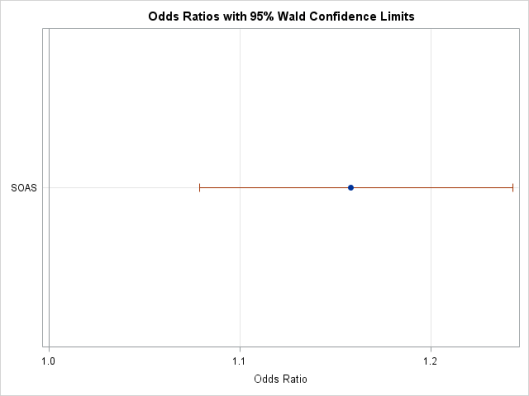
Proc Logistic data= <dataset> plots (only)= oddsratio ;
Class <outcome_var> <categorical_vars> ;
Model <outcome_var> (event=last) = SOAS;
RUN;

06 Saturday Aug 2016
Posted in Uncategorized
Proc Logistic data= <dataset> plots (only)= oddsratio ;
Class <outcome_var> <categorical_vars> ;
Model <outcome_var> (event=last) = SOAS;
RUN;
09 Saturday Jul 2016
Posted in Uncategorized
Problem: Proc Import will only check the first 20 rows of a spreadsheet to determine the data characteristics (type, length, etc).
Solution: Use GUESSINGROWS= <##> option to change the default (up to 32767).
Example:
02 Saturday Jul 2016
Posted in SAS
PROC Tabulate data= <library.dataset> ;
CLASS <Column-var_1> … <Column-var_n> ;
VAR <factor_1> … <factor_n> ;
TABLE ( <factor_1> … <factor_n> ) , (All <Column-var_1> … <Column-var_n> ) *( N Mean Std) ;
TABLE ( <factor_1> … <factor_m> ) , (All <Column-var_1> … <Column-var_n> ) *( N Median Qrange) ;
RUN;
PROC Tabulate data= <library.dataset> ;
CLASS <column-var_1> … <column-var_n> <factor_1> … <factor_n> ;
TABLE ( <factor_1> … <factor_n> ) , (All <column-var_1> … <column-var_n> ) *( Colpctn N ) ;
RUN;
29 Wednesday Jun 2016
Posted in Uncategorized
06 Saturday Jun 2015
Posted in Uncategorized
I’m using this macro to better understand and demonstrate how to do a given proc on multiple datasets with a similar name or prefix:
%macro multisort();
%do i =1 %to 3;
PROC Sort data=nbase_&i;
BY CHID;
RUN;
%end;
%mend;
%multisort;
31 Sunday May 2015
Posted in Uncategorized
%MACRO CRWLK (V,V1);
PROC CONTENTS
DATA=&V1
NOPRINT
OUT= &v
(KEEP= name type format label length engine nobs);
RUN;
DATA &V;
SET &V;
label_&v1=label;
&v=”&v1″;
DROP label;
RUN;
%MEND;
2. Then you will need to put this in your program:
%CRWLK(A,REG1); %CRWLK(B,REG2); %CRWLK(C,REG3);
PROC SORT DATA=A; BY name; RUN;
PROC SORT DATA=B; BY name; RUN;
PROC SORT DATA=C; BY name; RUN;
DATA Dataset1_set3;
MERGE A B C;
BY name;
track=compress(trim(a)|| trim(b)|| trim(c));
IF track=”REG1REG2REG3″ THEN variable_track=”variables found in all 3 datasets”;
*ELSE IF track=”REG1″ THEN variable_track=”variables found in set1 only”;
*ELSE IF track=”REG2″ THEN variable_track=”variables found in set2 only”;
*ELSE IF track=”REG3″ THEN variable_track=”variables found in set3 only”;
*ELSE variable_track=”variables found in sets 2 or 3″;
RUN;
3. UNCOMMENT/COMMENT out above to allow indication of which set is missing a variable.
28 Thursday May 2015
Posted in Uncategorized
Ok,
If you find yourself in over-ride (OVR) mode on a Mac and you are using Gedit, you find yourself stuck. The solution/problem is that the zero (0) on the number-pad will toggle you between INS and OVR.
Problem solved.
Dom
28 Thursday May 2015
Posted in Uncategorized
Given:
If a variable is coded from 1 to 10 and can hold any number values, then we have two problems:
a) parsing out the values
b) differentiating between ‘1’ and ’10’
For example, lets say we have a variable CD18 that is defined as “Who took the blood sugar?”, and we allow the participant to answer “check all that apply”:
(1) Mother (2) Father
(3) Grandmother (4) Grandfather
(5) Sister (6) Brother
(7) Aunt (8) Uncle
(9) Other Relative (10) Non-Relative
The problem is that SAS will import a string of values. In Python we might call it a list of strings. For example if the Mother and Sister had recorded the blood sugar, CD18 might = “15”, however if the Father had taken the measurement then CD18 is coded “2”. What happens if the participant indicated a non-relative?
If you parse for the presence of a ‘1’ in the string, you will miss information or could have a misclassification bias. Instead you need to use logic statements to better parse the data.
/* SCANNING for Mother */
IF CD18 = ” THEN CD18_mother = .;
ELSE IF (Index(CD18, ‘1’) ^=0) AND (Substr(CD18,2,1) ^= “0”) THEN CD18_mother = 1;
ELSE CD18_mother =0;
/* SCANNING for Father */
IF CD18 = ” THEN CD18_father = .;
ELSE IF Index(CD18, ‘2’) ^=0 THEN CD18_father = 1;
ELSE CD18_father =0;
/* SCANNING for Grandmother */
IF CD18 = ” THEN CD18_grandmother = .;
ELSE IF Index(CD18, ‘3’) ^=0 THEN CD18_grandmother = 1;
ELSE CD18_grandmother =0;
/* SCANNING for Grandfather */
IF CD18 = ” THEN CD18_grandfather = .;
ELSE IF Index(CD18, ‘4’) ^=0 THEN CD18_grandfather = 1;
ELSE CD18_grandfather =0;
/* SCANNING for Sister */
IF CD18 = ” THEN CD18_sister = .;
ELSE IF Index(CD18, ‘5’) ^=0 THEN CD18_sister = 1;
ELSE CD18_sister =0;
/* SCANNING for Brother */
IF CD18 = ” THEN CD18_brother = .;
ELSE IF Index(CD18, ‘6’) ^=0 THEN CD18_brother = 1;
ELSE CD18_brother =0;
/* SCANNING for Aunt */
IF CD18 = ” THEN CD18_aunt = .;
ELSE IF Index(CD18, ‘7’) ^=0 THEN CD18_aunt = 1;
ELSE CD18_aunt =0;
/* SCANNING for Uncle */
IF CD18 = ” THEN CD18_uncle = .;
ELSE IF Index(CD18, ‘8’) ^=0 THEN CD18_uncle = 1;
ELSE CD18_uncle =0;
/* SCANNING for Other-Relative */
IF CD18 = ” THEN CD18_other = .;
ELSE IF Index(CD18, ‘9’) ^=0 THEN CD18_other = 1;
ELSE CD18_other =0;
/* SCANNING for Non-Relative */
IF CD18 = ” THEN CD18_non = .;
ELSE IF Index(CD18, ‘0’) ^=0 THEN CD18_non = 1;
ELSE CD18_non =0;
26 Wednesday Nov 2014
Posted in Uncategorized
Tags
Changes must be in a data-step.
If you are recoding an existing variable, you may need to come back in and rename the new variable (NUMERIC_var) back to the original (CHAR_var) name so as to be consistent with your variable dictionary.
The Input function in SAS will take the form: “Input (variable, format).” Specify the numeric format that you want to create, but for dates this will also depend on the character contents. If you are capturing dates, then “2014-01” is a different than “01-20-2014.”
EXAMPLE
DATA mydataset_NEW;
SET mydataset;
NUMERIC_var = Input ( CHAR_var, 3.0); /* for simple conversion */
DATE_var = Input ( CHAR_var, date9.); /* for dates */
.
.
.
RUN;
22 Saturday Nov 2014
Posted in Uncategorized
There are many specific packages you can use, but R is the most compressive free package available. To begin go to
You will need to navigate to the download pages (http://cran.r-project.org/mirrors.html). From this list of “mirror sites,” choose the closest to you.
You will then have the opportunity to choose which version to download, depending on your operation system (Mac, Windows, or Linux). Use the links for “Precompiled binary distributions” at the top of the page and not the “source code.”
Note, that you will usually be directed to download the most recent “build” or version of R for your operation system (OS), but if you have an older version of an OS then look for the links for this older system as the newer versions of R may not work as well for you. This is NOT likely to be an issue unless you are using Windows XP or older, but if you have problems running R, you might consider installing an older version of R.
Next you may want to download specific packages so you can do specialized analysis in R. For that blog, stay tuned!
